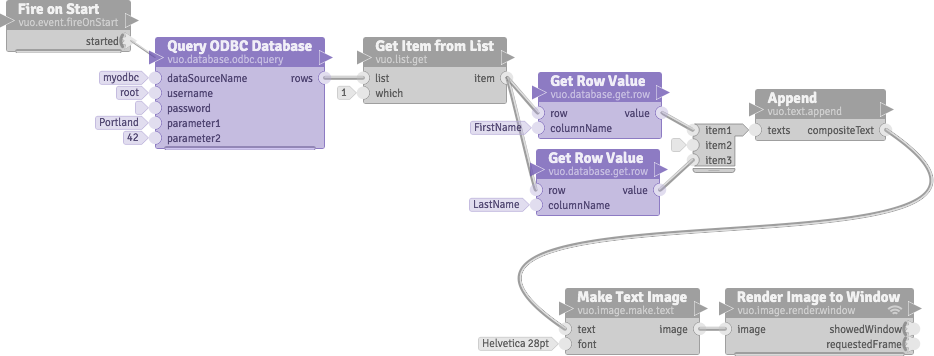
It would be great to be able to connect to various databases (ODBC, SQL, Postgres etc.), with structured data loading of XML, JSON, CSV, TXT file types (I see this is listed elsewhere in the roadmap) - including multidimensional lists/arrays/matrices.
Of particular interest would be the ability to query NetCDF files via a THREDDS server, using URL strings to query structured scientific data via OPenDAP. This would open up Vuo for scientific visualisation development (my research area) and take it leaps and bounds beyond Quartz Composer. In addition, if some functionality similar to d3.js (e.g. standard graphing types) and WebGL support was implemented - the Data Scientist mind would boggle, given the limits of MatPlotLib, Mayavi etc.
Application scenario: Vuo composition as visualisation front-end for oceanographic data (NetCDF) on a (e.g.) THREDDS server, interaction via Leap and wand devices, 3d mouse, enabling tagging of data for subsequent computational routines in Python etc.
@Smokris Should the different names of these 2 related feature requests not be updated for a better split ?
Somehow confusing for people like me being no real experts in Databases. Titles don’t really show the differences (if there are any).
It’s a bit complicated: the premise behind this request is the ability to make OPeNDAP requests (programmatically conformed URL strings) to a THREDDS server (Unidata NCAR TDS https://www.unidata.ucar.edu/software/thredds/current/tds/) to sub-set NetCDF data structures stored within an XML data catalogue. NetCDF provides self-describing data structures, susceptible to programmatic queries; THREDDS/OPeNDAP/NCAR-command language affords dynamic concatenation of virtual datasets of heterogenous datatypes.
But the real issue is that the graphics are not great: MatPlotLib-type science graphs. Fine for publication, no OpenGL, no realtime interaction. Very basic stuff - that omits the enormous & key human perceptual ability with animation and interaction. (though look at e.g. visPy, mayavi for Python.)
But: first you need a question (presuming some fore-knowledge of the data, its type, dimensions etc.) and then an application for it - e.g. detecting weather patterns, ocean patterns, migration of species - something to ask. (via e.g. a repository of wave-height data of a sea on Earth (but it could be on Titan)). There might be other parameters - multidimensional data such as RMS, Max wave height, Means, Frequency etc - all stored in a NetCDF file with embedded metadata.
Big Question: Can one make ignorant queries of data via a TDS or via a Ferret LAS (http://ferret.pmel.noaa.gov/Ferret/ - tutorial video - http://ferret.pmel.noaa.gov/tutorials/LAS_animation_tutorial.swf)
And once you’re in the process of making interesting queries, via conformed enquiries, the big thing that Vuo could enable is innovative ways to display and interact with them. Not only for scientists but for creative artists as well: unlocking really enormous data resources for innovative public display and scientific insight. The problem is that this stuff is all locked up in file formats and patterns of data query that do not ‘talk to each other’, so to speak - not only programmatically, but empirically as well.
I hope this was a bit illuminating - it’s complex, as I said. It’d be wonderful to be able to open this sort of data up to new modes of enquiry via a visual programming paradigm & yes, I’m working towards some $$ for this - but it’ll take time. It’d be nice to work out a good strategy.
Anyway, my five cents. :)
If they are quite the same they could be merged, if different, perhaps the titles should be updated for a better comprehension.
If they are quite the same, merging them will give you more votes for the request, and therefore more chance to be implemented (instead of users casting some votes here or there).
And if they are different, an updated title would allow users to see at a glance ah ok this is about this and that is about that ;)
And perhaps remove the beginning of the feature request because there is this specific feature request for that here : Structured Data Loading XML, JSON …. Again, could mislead votes ;) My 2 penny, just an idea ;)
Yep - I see what you mean. Maybe my URLS are getting confused. I’d drop the the “Query scientific databases via OPeNDAP” and make it a simple “Query Scientific Databases” - because there are lots of ways to query them and lots of types of them - we need something very flexible & clever. Let a thousand flowers bloom! Combine by all means - if it means more eyes on a common purpose with more creativity and action, then of course: let the sun shine! Thanks :)
Each of those 2 feature requests describes a different database protocol to implement. We’d be happy to consider additional database protocols — each protocol should be a separate feature request, since each protocol will take a substantial amount of time to implement, and we’d like to know what the community thinks each protocol’s priority should be.