@bodysoulspirit I get lucky sometimes!
Comb list is for the visual part only, I’ll come back to the implementation but you have to think in terms of samples and bits in relation to the bytes you work with. This might cover things you already know, but I can give a simple breakdown of it for others that might be interested as well. For audio, samples determine the pitch resolution, and bit-depth the amplitude resolution. When we speak of a 44.1KHz 16bit audio file, we mean that we have sampled the analog signal 44 100 times per second, with a quantization (rounding to nearest) of 16 bit = 65 536 different amplitude (loudness) levels.
Taking this over to byte manipulation; If 1 second of audio data is 44 100 samples, and there are 2 bytes per sample to give the 16 bits (there are usually 8 bits in a byte), you have 88 200 bytes for that second. Since the bytes are little endian it means that the first byte of a pair of two contains the detail information, while the second byte contains the coarse information. In practice the second byte place the amplitude into a coarse quantization of 256 levels (8 bit) from min(0) to max(255). The first byte place the amplitude into a fine quantization of 256 levels between two values in the *second *byte giving the total of 65 536 levels of amplitude.
That one second of audio is then represented in Vuo by a list of 88 200 integers with the Get Data Bytes node. If you combine the bytes to get the proper 44 100 samples with a resolution of 65 536 each, it would require a screen with a pixel resolution of 44 100px X 65 536px to display all of the detail. Undoubtedly cool, but unrealistic for most people at this time (and even if it were probable, it would be unnecessary as you wouldn’t see the detail). In addition, you want to avoid processing the parts you don’t need, as that would use a lot of resources for no benefit.
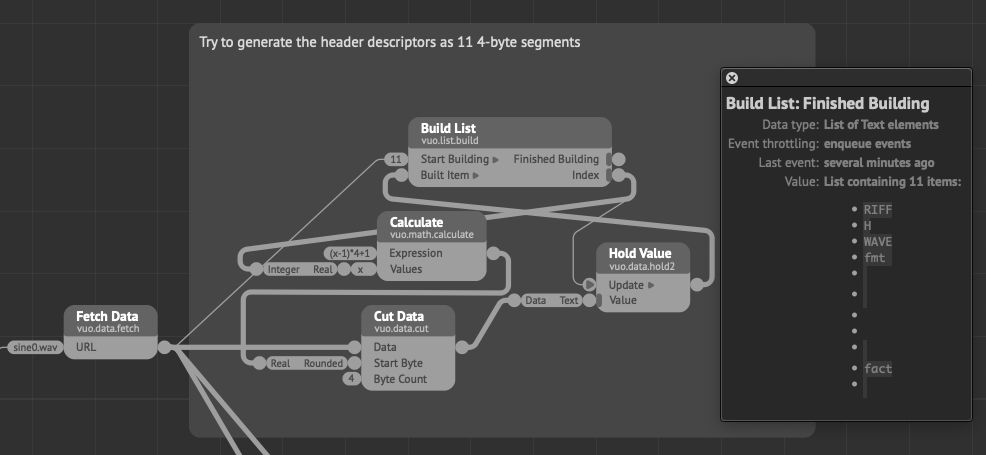
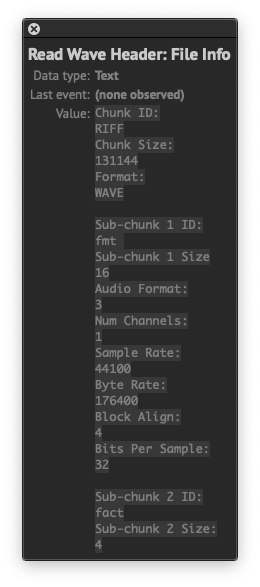
This is where we can start cutting away the data we don’t need to display. First of all is the header which by the spec is 44 bytes long. Then we don’t need the fine information carried by the first byte of data, meaning that we can skip that one and start at byte 46 using the Cut Data node. Something to note here is that since all the samples comes in pairs of 2, an odd number will always be the fine data, while an even number will always be the coarse data you want if you skip further ahead. If we now look at what we have, it’s still a list of 44 100 numbers for that second. As this is still far more than what’s needed for display, we can use the comb list to chop away more of the data before sending it to a mesh/object. So from the Cut Data node you can connect a Get Data Bytes node (which will give you a list of integers) and connect that one to a Comb List node. The Comb List works by specifying how many items in the list you want to keep, and how many you want to throw away. Here you want to keep 1 (as the next item would be the “fine” byte), and then skip an odd number until the number of points you get from it is a reasonable amount. If you keep 1 and skip 9, you effectively divide the list by 10, giving you 4 410 items in the list. If you skip 999, you divide by about 1000, giving you 45 items. Finding the suitable amount here for your display and sample length will take some tweaking. Smaller is better though as huge lists can be quite resource intensive.
As for 0s, if there is 1 millisecond of silence at the start of your wave data, it means that you’ll have 44 samples with a value of 0, and a list of 88 bytes with a value of 0 through the Get Data Bytes node. This will onlsy show 0s at the output port. If the length of silence is unknown, you could try scrubbing through your file using the starting point of the Cut Data node, and just add an offset to the byte count input with an Add node until something shows up. Or you could try locating the starting sample in an audio editor (probably faster/more accurate).
Note that this is only valid for a proper WAVE file as well. I’m not sure what the difference is to AIFF, but it could involve the header and the endianness of the data, so that would also have to be checked. Compressed formats (.mpX) will probably require decoding before something useful can be pulled from this approach.