Oh, and you have an offset from the input in your lines. Your list starts at the beginning of the line, but the control signal doesn’t come in until where the linear behaviour ends. This is probably why the waves are out of sync as well. Try cutting the input list going to the line object node from the beginning until it syncs up/starts at the wave.
Oh, and you have an offset from the input in your lines. Your list starts at the beginning of the line, but the control signal doesn’t come in until where the linear behaviour ends. This is probably why the waves are out of sync as well. Try cutting the input list going to the line object node from the beginning until it syncs up/starts at the wave.
Thank you, that’s helpful, I’ll try – maybe something to do with needing the file to play to the end, then enqueue, then build the graph? Maybe a properly placed Spin Off Event would solve it? By the way, the “wavetable” here is one .wav file with 16 waveforms one after the other. I’ll have another look at using Make Waveform Image. As long as the 16 slices can be extracted from the wavetable file and lined up with sample accuracy, then I’ll go with whatever graphic method works best, or works period. I’ll see how the orthographic camera performs – actually the line strip “ribbon” gets wonky, changes from start to end with the ortho camera, wondering if there’s a way to flatten that view and lose the ribbon effect so all line weight and thickness is the same.
If you’re not scared of some heavy nerding, you can also just get the bytes from the wav files via the Data nodes and convert the sample range from the file to the Y-values you need. That way you get straight to the data you want instead of going through a build/process list step.
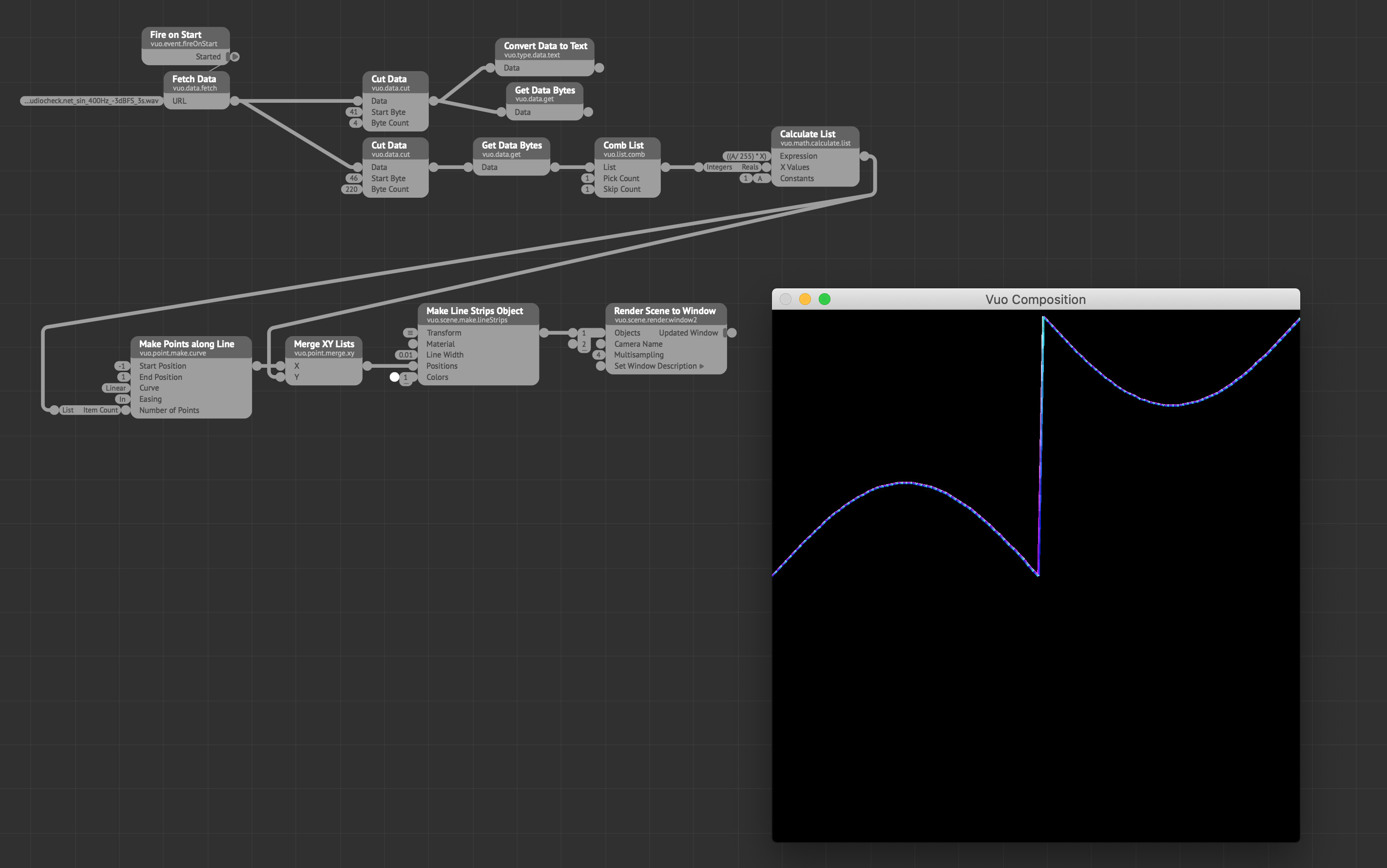
Be aware of the endianness of the wav data (Stackoverflow look at the second answer/The Canonical WAVE file format). Although the data starts at byte offset 45, it’s little-endian meaning that you want to start at byte offset 46, and skip every other byte as you won’t need the details for a display anyways. You can probably skip even more bytes in total, just add 2 to the skip count to decrease the resolution…
I’m too slow to figure out the formula, but you also probably want to shift all values above 127 to be in the negative range. Since the byte values are naturally unsigned they are subtracted from the maximum byte value (255).
2 Likes
The calculate list formula is:
(((((Height/ 255) * X) - (-(Height/2))) % ((Height/2) - (-(Height/2)))) + ((Height/2) - (-(Height/2)))) % ((Height/2) - (-(Height/2))) + (-(Height/2))
to deal with conversion from 8-bit to Vuo coordinates and place the parts correctly.
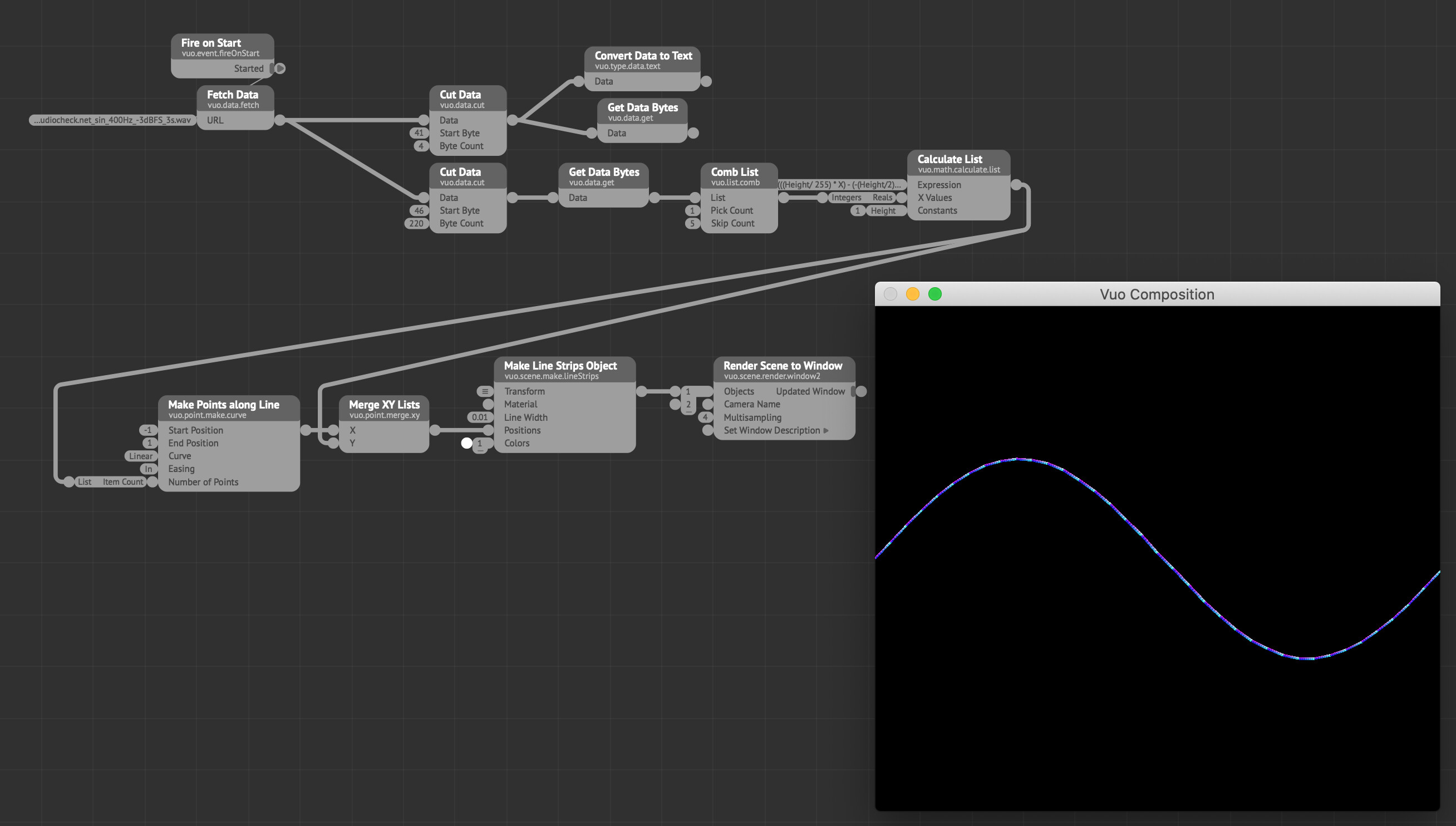
@MartinusMagneson, this is f-ing awesome! Thank you very much for doing the leg work on that. This is more what I was hoping for, being able to unpack the .wav file raw data. And thank you for sharing that 8-bit to Vuo coordinate conversion formula, would have landed there somehow.
I still need some way to isolate each waveform cycle, some % op scenario. So building a list of the 16 consecutive waveform cycles in the wavetable is still a likely outcome, which then is versatile for scaling, color, manually moving through the wavetable, possibly displaying phase shifts, etc.
Ps. what tools were you using in Vuo to see what data you had? Were you monitoring the data with Console?
1 Like
By accident just found @alexmitchellmus wavetable synth node set in the node gallery. That’s on the mark here, too. Very cool.
I just looked at the header data with the two loose nodes at the top to confirm the data according to the spec. For the data itself I looked at the output object which confused me for a bit until I remembered the endian-thing. If you know the sample size per cycle it’s just a matter of setting the byte count (Cut Data) to the double of the samples.
The wave data itself starts at byte 45 after the header, and from what I understand use two bytes per sample. There is no direct data → samples conversion (maybe a FR is in place?), but you might get lucky with converting a real list to audio. To do so (in theory) you can feed the output from the Cut Data to a Deinterleave list where the second list gets calculated with (1/256) x ListItem and the first list would be calculated with ((1/256)/256) x ListItem
(The proper term is probably calculation, not formula. I’ve been baking too much the last 7 months…)
Awesome, thank you. I’ll see what I can put together.
(Yeah, man, these past months have been like no other… not to mention politics, so easy to let that @#$% take over the psyche…)
1 Like
You also have to add the two lists together again, forgot to mention that!
Damn Martinus, you do really have some nice skills in a broad range of domains ;)
Amazing.
No luck yet with my wavetable files. I’m a little confused at the moment how to set up Comb List or ?. Viewing only the first part of the list in the output port display, looks like there are a lot of extra zeroes in my file, and I am not sure about the pattern and what/how to skip. Why so many zeroes? @MartinusMagneson as you mentioned, it seems that I should be able to “resample”. Need to bear down on the numbers. It would be nice to tame the data to get back to something resembling the 32768 total samples → 16x2048, i.e., straightforward power of 2 stuff…
@bodysoulspirit I get lucky sometimes!
Comb list is for the visual part only, I’ll come back to the implementation but you have to think in terms of samples and bits in relation to the bytes you work with. This might cover things you already know, but I can give a simple breakdown of it for others that might be interested as well. For audio, samples determine the pitch resolution, and bit-depth the amplitude resolution. When we speak of a 44.1KHz 16bit audio file, we mean that we have sampled the analog signal 44 100 times per second, with a quantization (rounding to nearest) of 16 bit = 65 536 different amplitude (loudness) levels.
Taking this over to byte manipulation; If 1 second of audio data is 44 100 samples, and there are 2 bytes per sample to give the 16 bits (there are usually 8 bits in a byte), you have 88 200 bytes for that second. Since the bytes are little endian it means that the first byte of a pair of two contains the detail information, while the second byte contains the coarse information. In practice the second byte place the amplitude into a coarse quantization of 256 levels (8 bit) from min(0) to max(255). The first byte place the amplitude into a fine quantization of 256 levels between two values in the *second *byte giving the total of 65 536 levels of amplitude.
That one second of audio is then represented in Vuo by a list of 88 200 integers with the Get Data Bytes node. If you combine the bytes to get the proper 44 100 samples with a resolution of 65 536 each, it would require a screen with a pixel resolution of 44 100px X 65 536px to display all of the detail. Undoubtedly cool, but unrealistic for most people at this time (and even if it were probable, it would be unnecessary as you wouldn’t see the detail). In addition, you want to avoid processing the parts you don’t need, as that would use a lot of resources for no benefit.
This is where we can start cutting away the data we don’t need to display. First of all is the header which by the spec is 44 bytes long. Then we don’t need the fine information carried by the first byte of data, meaning that we can skip that one and start at byte 46 using the Cut Data node. Something to note here is that since all the samples comes in pairs of 2, an odd number will always be the fine data, while an even number will always be the coarse data you want if you skip further ahead. If we now look at what we have, it’s still a list of 44 100 numbers for that second. As this is still far more than what’s needed for display, we can use the comb list to chop away more of the data before sending it to a mesh/object. So from the Cut Data node you can connect a Get Data Bytes node (which will give you a list of integers) and connect that one to a Comb List node. The Comb List works by specifying how many items in the list you want to keep, and how many you want to throw away. Here you want to keep 1 (as the next item would be the “fine” byte), and then skip an odd number until the number of points you get from it is a reasonable amount. If you keep 1 and skip 9, you effectively divide the list by 10, giving you 4 410 items in the list. If you skip 999, you divide by about 1000, giving you 45 items. Finding the suitable amount here for your display and sample length will take some tweaking. Smaller is better though as huge lists can be quite resource intensive.
As for 0s, if there is 1 millisecond of silence at the start of your wave data, it means that you’ll have 44 samples with a value of 0, and a list of 88 bytes with a value of 0 through the Get Data Bytes node. This will onlsy show 0s at the output port. If the length of silence is unknown, you could try scrubbing through your file using the starting point of the Cut Data node, and just add an offset to the byte count input with an Add node until something shows up. Or you could try locating the starting sample in an audio editor (probably faster/more accurate).
Note that this is only valid for a proper WAVE file as well. I’m not sure what the difference is to AIFF, but it could involve the header and the endianness of the data, so that would also have to be checked. Compressed formats (.mpX) will probably require decoding before something useful can be pulled from this approach.
Sharing my current stage, and my clear lack of knowledge. Still not quite getting the final result I need, digging in a little at a time, online research has not quite given me the whole picture, fragments here and there, stackoverflow, etc.
This is what I output right now:
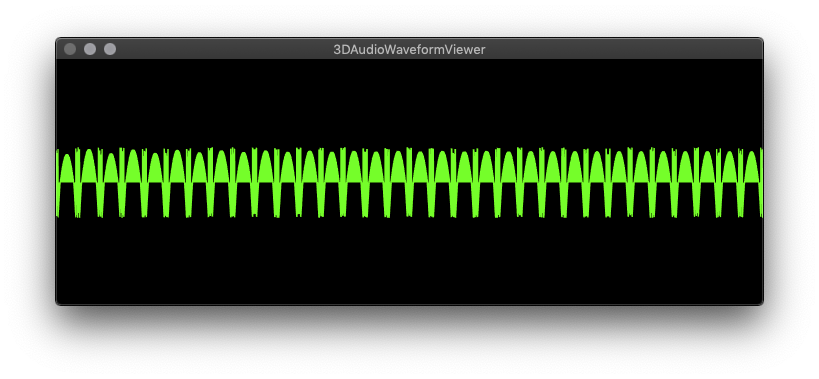
I don’t understand a number of things –
In order to get at least something that contains waveform like display, I need to set Cut Data start byte back to 45. Maybe this is because of the .wav file structure generated in the software I use (Plogue Bidule – uncompressed PCM)? Then there is the byte length of my file – 131153. How do I understand the header + remaining byte structure in relation to my 32768 sample length, 16-bit mono, etc.? I should double check, but I’d be really surprised if Bidule output anything other than clean, most universal .wav format. What makes most numerical sense is sample length*4 = 131072, which leaves 81 bytes left over – why? Then there is Comb List set to skip 5 – why every 6th byte in the list?
@MartinusMagneson – that 8-bit conversion calculation, I have not quite unpacked that, I want to understand the 8-bit integer conversion 'Get Data Bytes` is outputting, is the calculation something about uLaw conversion? Feeling the desire to simplify to generate a [-1,1] range then apply height scaling…
In general I am looking ahead a bit to having a reliable setup to handle a range of wavetable size and waveform cycle length.
Take a look at this page which apparently is the source for the previously referred to image: http://soundfile.sapp.org/doc/WaveFormat/. It has a better explanation of the header.
I think this discussion might go into a full tutorial (the wave format should be well suited for that), but you will have to check the header to determine the specifics of your wave file. My example was a mono file, but if you have a stereo file, it will intertwine the data for each channel. You can read this from the “Num Channels” in the header. Basically you’ll have to determine the pick and skip count by the data in the header, which should enable an automatic conversion and display of the files as well. I’ll need some time to type it up, but I already have the header extraction done.
Yeah, I have that WaveFormat page open, too. Looking forward to seeing how you unpack the header, I have been struggling with how to get readable parts out of it by converting data to text. For example:
I appreciate the tutorial approach, and the general effort and guidance. My project is still specific to wavetables. The .wav files I will use will always be mono, 16-bit, 44.1k, linear PCM – most standard .wav format. Once again, a wavetable is a series of 16 single cycle waveforms, each precisely 2048 samples long (no silence). Other wavetables have more or less waveforms and different cycle lengths, though likely always some 2^n (256-4096). This is a standard format for wavetables used in many wavetable soft synths. I want to slice the n waveforms into a 3D view.
@jersmi See if the attached files makes any sense to you, and I’d appreciate it if you have any feedback on it :)
You shouldn’t need the attached composition/module, but they can be handy as a reference
VuoDataTutorial.zip (2.24 MB)
2 Likes
Received, @MartinusMagneson. This is a very generous thing you have done. You mean you want feedback on the doc? I was able to follow along, nice job making the general comp sci info understandable for the likes of me, appears to have cleared up my questions, I’ll see when I try to apply it to my scenario. Could use a little polish, I suppose – section headers, esp. for general info and Vuo related, maybe a bit more at the end about applying the concepts to other file types (if this is a general tutorial). Could these built-in Vuo techniques be applied to image or 3D object data, glitch art, things as such? And that Calculate List section, I’m still wondering if that calc could/should be simplified with constants. At any rate, my turn to try and apply the concepts.
Ok, an issue. Turns out a bunch of the files I am using are 32-bit .wav files. Right now the Read Wave Header subcomp only handles “standard” 16-bit PCM. It will need an additional part (and maybe an if/then test?) to handle the extra byte chunk for format type 3/32-bit (see the non-PCM data table here):
http://www-mmsp.ece.mcgill.ca/Documents/AudioFormats/WAVE/WAVE.html
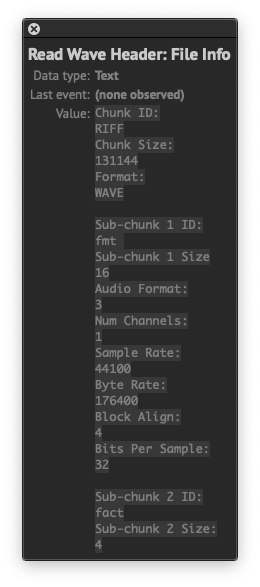
Here’s a mod of the Read Wave Header subcomp which adds the extra header chunks to read the longer header for 32-bit float files (non-PCM). Thanks again, @MartinusMagneson, that subcomp was super helpful. This one outputs a length in samples, which then allows a calculation for byte count of the audio data, hope I got it correct – sub-chunk 2 size * sample length.
Edit: I learned that the 32-bit float sound files I am using were generated with libsndfile, which automatically adds PEAK/16 byte chunks (discovered after adding the extra header chunks):
chunkID: PEAK
chunkDataSize: 16
There is a “feature” to PEAK that generates a normalized peak value/position structure, but I don’t know how to check if it is embedded in the data or not. Bottom line: I’m still trying to understand why my 32-bit float waveforms are not outputting correctly to the viewer (still look the same as the pic posted above), so being fuzzy about PEAK/16 keeps it on the table as a possible culprit.
mm.readWaveHeader2.vuo (13.6 KB)
Thanks for the feedback! I don’t always write simple/clear enough so it’s golden to get something like that to iron out the wrinkles. Vuo has a build in data to image node, but I’ll see about examples for other uses. The tutorial should possibly be split into chapters as well to give more bite-sized approaches to it, the full thing can take some time to get through.
With 32-bit files, you need to take the byte count more into consideration as you have 4 bytes per sample. I didn’t write much about automating this from the header data as it would get even longer (chaptering it out might be a way to include it). You can divide the byte-rate by the sample rate to get the bytes per sample, and use that output to set the Comb List pick/skip count.
Having more chunks means you’ll also have to offset the start of the read to 45 + the bytes of the additional chunks. Ideally there would be a “Find in Data” node (or something like that) for scanning the file and provide the byte location of the “DATA” chunk-ID. Then you’d be able to use that to get to the starting point relatively easy. For now I think it will have to be a manual process though.